Natural Language Processing Phases
Natural Language Processing (NLP) is the field of artificial intelligence that focuses on the interaction between computers and human language. It involves a series of stages or phases to process and analyze language data. The main phases of NLP can be broken down as follows.
We interact with language every day, effortlessly converting thoughts into words. But for machines, understanding and manipulating human language is a complex challenge. This is where Natural Language Processing (NLP) comes in, a field of artificial intelligence that empowers computers to understand, interpret, and generate human language. But how exactly do machines achieve this feat? The answer lies in a series of distinct phases that form the backbone of any NLP system.
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. NLP involves several stages or phases, each of which plays a crucial role in transforming raw text data into meaningful insights. Below are the typical phases of an NLP pipeline:
From Understanding to Action
These phases aren’t always completely separate, and they often overlap. Furthermore, the specific techniques used within each phase can vary greatly depending on the task and the chosen approach. However, understanding these core processes provides a crucial window into how machines are beginning to “understand” our language.
The power of NLP lies not just in understanding, but also in acting upon what it understands. From voice assistants and chatbots to sentiment analysis and machine translation, the applications of NLP are vast and rapidly expanding. As NLP technology matures, it will continue to revolutionize how we interact with machines and unlock new possibilities in nearly every aspect of our lives.
Phases of Natural Language Processing
1. Text Collection
Example: Gathering customer reviews, tweets, or news articles.
Description: This is the first step, where data is collected for processing. It can include scraping text from websites, using available datasets, or extracting text from documents (PDFs, Word files, etc.).
Lexical Analysis, The Foundation of Understanding: This first phase is all about breaking down the raw text into its basic building blocks, like words and punctuation marks. Imagine it like sorting Lego bricks by color and size.
- Stemming/Lemmatization: These techniques reduce words to their root forms, helping to group similar words together. “Running” and “ran” would both be reduced to “run.” Stemming is a simpler approach that just chops off endings, while lemmatization takes into account the context and produces dictionary-valid base forms.The raw text data is often noisy and unstructured, so preprocessing is the first step to clean and format it for further analysis. Lemmatization: Similar to stemming but more sophisticated, it involves reducing words to their lemma (e.g., “better” to “good”).
- Tokenization: This step involves splitting a text into individual units called “tokens.” These tokens could be words, punctuation, numbers, or even individual characters depending on the application. For example, the sentence “The cat sat on the mat.” would be tokenized into [“The”, “cat”, “sat”, “on”, “the”, “mat”, “.”].
- Stop Word Removal: Common words (e.g., “the”, “is”, “and”) that don’t contribute much meaning are often removed.Many common words, like “the,” “a,” “is,” and “of,” don’t contribute much to the meaning of a sentence. This step removes these “stop words” to reduce noise and improve processing efficiency.
- Lowercasing: Converting all text to lowercase to avoid distinguishing between “Apple” and “apple.”
- Removing Punctuation: Eliminating punctuation marks as they don’t typically add value for many NLP tasks.
- Stemming: Reducing words to their base or root form (e.g., “running” to “run”).
2. Text Representation
After preprocessing, the next step is to convert text into a format that can be fed into machine learning algorithms. Common methods include:
- Bag of Words (BoW): A simple model where each word is treated as a feature, and the text is represented by the frequency of words.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weighs the importance of words by considering their frequency in a document relative to their frequency in the entire corpus.
- Word Embeddings: Techniques like Word2Vec, GloVe, and FastText represent words as dense vectors in a high-dimensional space, capturing semantic meaning.
- Contextualized Embeddings: Models like BERT, GPT, and ELMo provide dynamic embeddings based on context, offering more accurate word representations.
- Description: Converting text into a numerical format that machine learning models can understand. Popular methods include:
- Example: The sentence “I love natural language processing” might be converted into a vector that represents its semantic meaning.
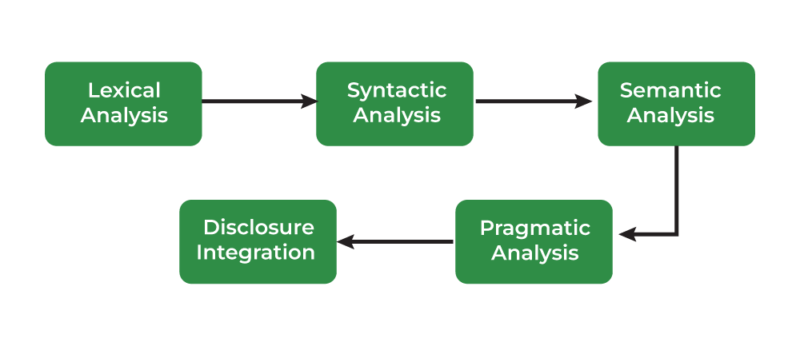
3. Syntactic Analysis: Understanding Sentence Structure
Word Sense Disambiguation: Analyzing the grammatical structure of sentences to understand how words are related. The result is often represented as a parse tree or a dependency tree.Many words have multiple meanings. This step aims to identify the correct meaning of a word based on its context. For example, consider the word “bank.” Is it a financial institution or the edge of a river? For the sentence “The cat sat on the mat,” syntactic analysis would determine the relationships between “cat,” “sat,” and “mat.
Named Entity Recognition (NER): This involves identifying and classifying named entities in the text, such as people, organizations, locations, and dates. This allows the system to extract key elements from a text and organize information.
Semantic Relationship Extraction: This process focuses on uncovering the relationships between these entities. For example, understanding that “Apple” is a “company” and that “Steve Jobs” was its “founder.” This helps understand the connections within the text.
- Part-of-Speech (POS) Tagging: This involves identifying the grammatical role of each word in a sentence, such as noun, verb, adjective, etc. For example, in “The cat sat”, “The” is a determiner, “cat” is a noun, and “sat” is a verb. Description: Identifying the grammatical components of a sentence, such as nouns, verbs, adjectives, etc. This helps in understanding the syntactic structure of the sentence.
- Example: In the sentence “The cat runs fast,” “The” is a determiner, “cat” is a noun, and “runs” is a verb.
- Parsing: This deeper analysis determines how words are grouped to form phrases and sentences. It constructs a parse tree that highlights the relationships between words according to grammar rules. This helps the system understand the underlying structure of the sentence.
- Dependency Parsing: This builds on parsing by identifying how words depend on each other. For instance, in “The cat ate the fish,” “ate” is the main verb and “cat” is its subject, while “fish” is its object.
4. Semantic Analysis
This phase focuses on understanding the meaning of words, phrases, and sentences.
- Named Entity Recognition (NER): Identifying proper names, such as people, organizations, locations, dates, etc. Identifying entities in the text such as names of people, places, organizations, dates, etc. In the sentence “Apple announced a new product in New York on January 15,” “Apple” is an organization, “New York” is a location, and “January 15” is a date.
- Word Sense Disambiguation: Determining the meaning of a word based on its context (e.g., distinguishing between “bank” as a financial institution and “bank” as the side of a river).
- Coreference Resolution: Identifying which words or phrases refer to the same entity in a text (e.g., “John” and “he”).
- Semantic Role Labeling: Assigning roles (e.g., agent, patient, goal) to words in a sentence to understand their relationships.
5. Pragmatic Analysis
This phase involves understanding the broader context of the text, including implied meaning, sentiment, and intent.
- Sentiment Analysis: Determining whether the text expresses a positive, negative, or neutral sentiment.
- Intent Recognition: Identifying the goal or purpose behind a text, especially in tasks like chatbots and virtual assistants (e.g., is the user asking a question or making a command?).
- Speech Acts: Recognizing the function of a statement (e.g., is it an assertion, question, request?).
6. Discourse Analysis: Beyond Single Sentences
Discourse analysis involves understanding the relationship between sentences or parts of the text in larger contexts, such as paragraphs or conversations.
- Coherence and Cohesion: Ensuring that the text flows logically, with proper links between ideas and sentences.
- Topic Modeling: Identifying the main themes or topics within a collection of documents (e.g., Latent Dirichlet Allocation, or LDA).
- Summarization: Reducing a document or text to its essential content, while maintaining its meaning. This can be extractive (picking parts of the text) or abstractive (generating a new summary).
- Description: Understanding the structure and coherence of longer pieces of text. This phase involves analyzing how sentences connect and flow together to form a coherent discourse.
- Example: Understanding that in a story, “John was tired. He went to bed early,” “He” refers to “John.”
- In the sentences “John went to the store. He bought some milk,” the coreference resolution identifies that “He” refers to “John.”
- This final phase looks at the context surrounding multiple sentences and paragraphs to understand the overall flow and meaning of the text. It’s like examining the context around the Lego structure to understand its role within a larger landscape.
- Anaphora Resolution: This involves identifying what a pronoun refers to. For example, in “The dog chased the ball. It was fast,” “it” refers to the “ball”.
- Coherence Analysis: This step analyzes the logical structure and connections between different parts of a text. It helps the system identify the overall message, argument, and intent of the text.
7. Text Generation
This phase involves generating human-like text from structured data or based on a given prompt.
- Language Modeling: Predicting the next word or sequence of words given some context (e.g., GPT-3).
- Machine Translation: Translating text from one language to another.
- Text-to-Speech (TTS) and Speech-to-Text (STT): Converting written text into spoken language or vice versa.
8. Post-Processing and Evaluation
After the main NLP tasks are performed, results need to be refined and evaluated for quality.
- Evaluation Metrics: Measures like accuracy, precision, recall, F1-score, BLEU score (for translation), ROUGE score (for summarization), etc., are used to assess the performance of NLP models.
- Error Analysis: Identifying and understanding errors to improve model performance.
9. Application/Deployment
Finally, the NLP model is integrated into real-world applications. This could involve:
- Chatbots and Virtual Assistants: Applications like Siri, Alexa, or customer service bots.
- Search Engines: Improving search relevance by better understanding queries.
- Machine Translation Systems: Automatic language translation tools (e.g., Google Translate).
- Sentiment Analysis Systems: For analyzing public opinion in social media, reviews, etc.
- Speech Recognition Systems: For converting speech into text and vice versa.
10. Machine Learning/Deep Learning Models
Reinforcement Learning: Used in systems like chatbots where actions are taken based on user interaction.Key Considerations
Description: Once the text has been processed, various machine learning or deep learning models are used to perform tasks such as classification, translation, summarization, and question answering.
Supervised Learning: Algorithms are trained on labeled data to perform tasks like sentiment analysis, classification, or named entity recognition.
Unsupervised Learning: Algorithms are used to find patterns in unlabeled data, like topic modeling or clustering.
- Multilingual NLP: Handling text in multiple languages and addressing challenges like translation, tokenization, and word sense disambiguation.
- Bias in NLP: Addressing bias in data and models to ensure fairness and inclusivity.
- Domain-Specific NLP: Customizing NLP for specialized fields like medicine (bioNLP), law (legal NLP), or finance.
These phases represent a typical NLP pipeline, but depending on the application and problem at hand, not all phases may be required or performed in the same order.
Conclusion
In conclusion, understanding the phases of NLP isn’t just a technical exercise; it’s a journey into the very heart of how machines are learning to speak our language. As we progress in this field, we’ll continue unlocking new ways for humans and machines to communicate and collaborate seamlessly.
Each of these phases plays a crucial role in enabling NLP systems to effectively interpret and generate human language. Depending on the task (like machine translation, sentiment analysis, etc.), some phases may be emphasized more than others.